@Thierry : Cet article fait suite à « Préparez-vous à la mise en service de D365HR », mais il est général dans la mise en oeuvre d’un projet Dynamics. Il faut alimenter la base avec des données, qu’elle vienne d’un ancien système ou que l’on parte de zéro. Opérations que l’on peut faire 2, 3, 4 fois dans la vie du projet avant le GoLive. D365BC (Navision) utilise « RapidSart » pour gérer les données. D365FO et D365HR utilise le même outil ‘Entités de données » que nous allons voir ci-après :
Présentation de la gestion des données
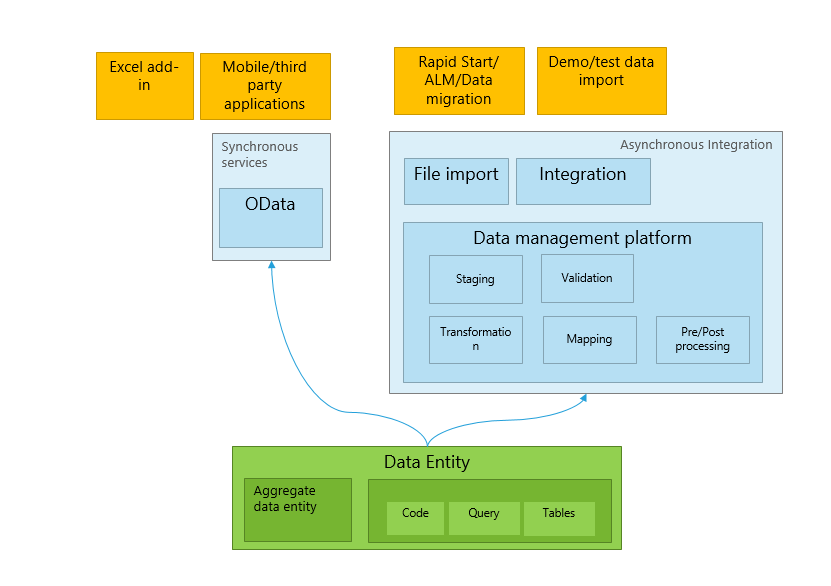
Cette rubrique décrit comment vous pouvez utiliser l’infrastructure de gestion des données pour gérer les entités de données et les packages d’entités de données dans Finance and Operations.
Le cadre de gestion des données comprend les concepts suivants:
- Entités de données – Une entité de données est une abstraction conceptuelle et une encapsulation d’une ou plusieurs tables sous-jacentes. Une entité de données représente un concept ou une fonctionnalité de données commun, par exemple, les clients ou les fournisseurs. Les entités de données sont destinées à être facilement comprises par les utilisateurs familiarisés avec les concepts commerciaux. Une fois les entités de données créées, vous pouvez les réutiliser via le complément Excel, les utiliser pour définir des packages d’importation / exportation ou les utiliser pour des intégrations.
- Projet de données – Un projet qui contient des entités de données configurées, qui incluent des options de mappage et de traitement par défaut.
- Travail de données – Un travail qui contient une instance d’exécution du projet de données, des fichiers téléchargés, une planification (récurrence) et des options de traitement.
- Historique des travaux – Historiques de la source à la mise en scène et de la mise en attente aux travaux cibles.
- Package de données – Un fichier compressé unique qui contient un manifeste de projet de données et des fichiers de données. Ceci est généré à partir d’un travail de données et utilisé pour l’importation ou l’exportation de plusieurs fichiers avec le manifeste.
L’infrastructure de gestion des données prend en charge l’utilisation d’entités de données dans les scénarios de gestion de données de base suivants:
- Migration de données
- Configurer et copier des configurations
- L’intégration
Entités de données
Les entités de données fournissent une abstraction conceptuelle et une encapsulation du schéma de table sous-jacent qui représente des concepts et des fonctionnalités de données. Dans Microsoft Dynamics AX 2012, la plupart des tables, comme les tables Client et Fournisseur, ont été dé-normalisées et divisées en plusieurs tables. Cela a été bénéfique du point de vue de la conception de la base de données, mais a rendu difficile l’utilisation pour les implémenteurs et les éditeurs de logiciels indépendants sans une compréhension approfondie du schéma physique. Les entités de données ont été introduites dans le cadre de la gestion des données pour être utilisées comme une couche d’abstraction à comprendre facilement à l’aide de concepts commerciaux. Dans les versions précédentes, il existait plusieurs façons de gérer les données, telles que les compléments Microsoft Excel, AIF et DIXF. Le concept d’entités de données combine ces différents concepts en un seul. Une fois les entités de données créées, vous devriez pouvoir les réutiliser pour un complément Excel, import / export ou intégration. Le tableau suivant présente les principaux scénarios de gestion des données.
| Migration de données | Migrez les données de référence, de base et de document à partir de systèmes hérités ou externes. |
| Configurer et copier la configuration | Copiez la configuration entre l’entreprise / les environnements.Configurez des processus ou des modules à l’aide de l’environnement Lifecycle Services (LCS). |
| L’intégration | Intégration basée sur les services en temps réel.Intégration asynchrone. |
Migration de données
À l’aide de l’infrastructure de gestion des données, vous pouvez rapidement migrer les données de référence, de base et de document à partir de systèmes hérités ou externes. Le framework est conçu pour vous aider à migrer rapidement les données à l’aide des fonctionnalités suivantes:
- Vous ne pouvez sélectionner que les entités dont vous avez besoin pour migrer.
- Si une erreur d’importation se produit, vous pouvez ignorer les enregistrements sélectionnés et choisir de poursuivre l’importation en utilisant uniquement les bonnes données, en choisissant ensuite de corriger et d’importer les données incorrectes plus tard. Vous pourrez continuer partiellement et utiliser des erreurs pour trouver rapidement des données erronées.
- Vous pouvez déplacer des entités de données directement d’un système à un autre, sans avoir à passer par Excel ou XML.
- Les importations de données peuvent être facilement planifiées à l’aide d’un lot, ce qui offre une flexibilité lorsqu’il est nécessaire de s’exécuter. Par exemple, vous pouvez migrer à tout moment des groupes de clients, des clients, des fournisseurs et d’autres entités de données dans le système.
Configurer et copier la configuration
Vous pouvez utiliser l’infrastructure de gestion des données pour copier des configurations entre des entreprises ou des environnements et configurer des processus ou des modules à l’aide de Microsoft Dynamics Lifecycle Services (LCS).
La copie de configurations vise à faciliter le démarrage d’une nouvelle implémentation, même si votre équipe ne comprend pas en profondeur la structure des données à saisir, les dépendances de données ou la séquence pour ajouter des données à une implémentation.
Le cadre de gestion des données vous permet de:
- Déplacer des données entre deux systèmes similaires
- Découvrir les entités et les dépendances entre les entités pour un processus ou un module métier donné
- Gérez une bibliothèque réutilisable de modèles de données et d’ensembles de données
- Utilisez des packages de données pour créer des entités de données incrémentielles. Les entités de données peuvent être séquencées à l’intérieur des packages. Vous pouvez nommer des packages de données, qui peuvent être facilement identifiables lors de l’importation ou de l’exportation. Lors de la création de packages de données, les entités de données peuvent être mappées aux tables intermédiaires dans des grilles ou à l’aide d’un outil de mappage visuel. Vous pouvez également glisser-déposer manuellement des colonnes.
- Affichez les données lors des importations afin de pouvoir comparer les données et vous assurer qu’elles sont valides.
Travailler avec des entités de données
Les sections suivantes fournissent des instantanés rapides des différentes fonctionnalités de la gestion des données à l’aide d’entités de données. L’objectif est de vous aider à élaborer des stratégies et à prendre des décisions efficaces sur la meilleure façon d’utiliser les outils disponibles lors de la migration des données. Vous trouverez également des trucs et astuces pour utiliser efficacement chaque zone lors de la migration des données. Une liste des entités de données disponibles pour chaque zone peut également être trouvée avec les séquences de données suggérées, montrant les dépendances des données. Microsoft fournit des packages de données qui peuvent être trouvés sur Lifecycle Services (LCS) comme guide initial. Les informations contenues dans ce document peuvent être utilisées comme guide pour créer vos propres packages. La description de chaque entité de données montre ce que contient l’objet et s’il est nécessaire pendant la migration des données.
Séquençage
Il existe deux types de séquençage à prendre en compte lors de l’utilisation d’entités de données.
- Séquençage des entités de données dans un package de données
- Séquencer l’ordre des importations de packages de données
Séquence d’entités de données dans un package de données
- Lorsqu’un utilisateur ajoute des entités de données à un projet de données, par défaut, une séquence est définie pour l’ordre dans lequel les entités seront chargées. La première entité ajoutée au projet sera définie comme la première entité à charger, la prochaine entité ajoutée sera la deuxième, la prochaine entité sera la troisième, et ainsi de suite.Par exemple, si un utilisateur a ajouté deux entités dans cet ordre, les codes de taxe sur les ventes et les groupes taxe de vente , puis les codes de la taxe de vente est attribué une séquence d’entité 1.1.1 et groupes taxe de vente est attribué une séquence d’entité 1.1.2 . Le niveau de séquence indique que la deuxième entité ne démarrera pas le processus d’importation tant que le premier niveau ne sera pas terminé.
- Pour afficher ou modifier une séquence, cliquez sur le bouton Séquence d’entités dans le volet Actions du projet de données.

- Dans la séquence d’entités du groupe Définition, vous pouvez voir les unités d’exécution et la séquence. Vous pouvez modifier la séquence en sélectionnant l’entité de données dans la liste, en définissant une unité d’exécution ou une séquence différente dans le niveau, puis en cliquant sur Mettre à jour la sélection . Après avoir cliqué sur Mettre à jour la sélection , l’entité se déplacera vers le haut ou vers le bas dans la liste des entités.
Exemple
La capture d’écran suivante montre la séquence d’entités définie pour le package de données Sales Tax CodeGroups.
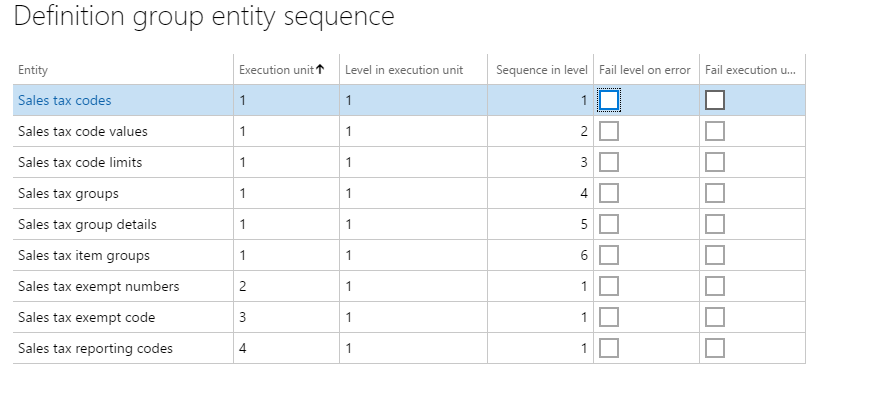
Pour importer avec succès les codes et les groupes de taxe de vente, les codes et les détails de la taxe de vente doivent d’abord être chargés, avant que les groupes de taxe de vente puissent être importés. Les codes et les groupes de taxe de vente sont tous dans l’unité d’exécution = 1, mais les séquences sont dans l’ordre dans lequel elles seront importées. D’autres entités de taxe de vente liées qui ne dépendent pas d’autres entités de données chargées sont incluses dans le package. Par exemple, les numéros exonérés de taxe de vente sont définis dans sa propre unité d’exécution = 2. Cette entité de données commencera à se charger immédiatement car il n’y a pas de dépendances sur d’autres entités qui se chargent avant elle.
Importations de packages de données de séquence
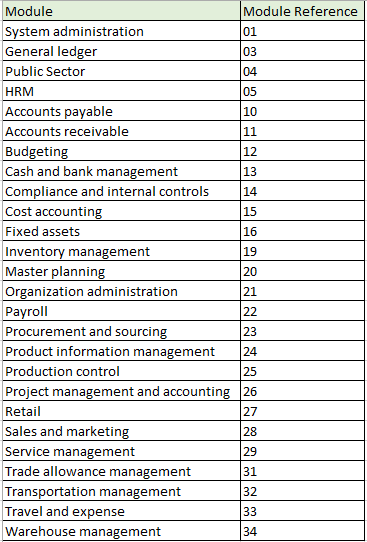
Afin de réussir le chargement des données, il est important de définir le bon ordre d’importation des packages de données, en raison des dépendances qui existent dans et entre les modules. Le format de numérotation créé pour les packages de données dans LCS est le suivant:
- Premier segment: Module
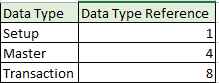
- Deuxième segment: type de données (configuration, maître, transaction)
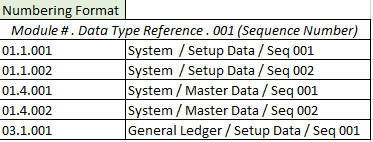
- Troisième segment: numéro de séquence
Les tableaux suivants fournissent plus d’informations sur le format de numérotation par défaut.
Numéros de module
Numéros de type de données
Numéro de séquence
Les packages de données suivent le numéro de séquence, suivi de l’abréviation du module, puis d’une description. L’exemple suivant montre les packages de données du grand livre.
Cartographie
Lorsque vous travaillez avec des entités de données, le mappage d’une entité à une source est automatique. Le mappage automatique des champs peut être remplacé si nécessaire.
Afficher le mappage
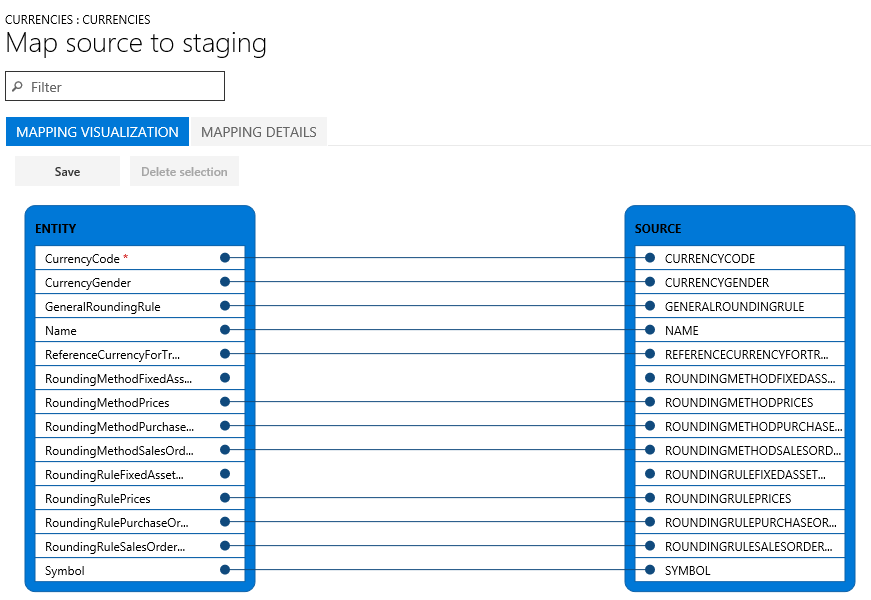
Pour voir comment une entité est mappée, recherchez la vignette de l’entité dans le projet, puis cliquez sur Afficher la carte .
Nous fournissons une vue de visualisation cartographique (par défaut) et une vue détaillée de la cartographie. Un astérisque rouge (*) identifie tous les champs obligatoires dans une entité. Ces champs doivent être mappés pour fonctionner avec l’entité. D’autres champs peuvent être démappés selon les besoins lorsque vous travaillez avec l’entité.
- Pour annuler le mappage d’un champ, mettez en surbrillance le champ dans l’une des colonnes ( Entité ou Source ), cliquez sur Supprimer la sélection , puis sur Enregistrer . Après l’enregistrement, fermez le formulaire pour revenir au projet.
Le mappage de champ de la source à la mise en scène peut également être modifié après l’importation en utilisant le même processus.
Régénérer une carte
Si vous avez étendu une entité (champs ajoutés) ou si le mappage automatique semble incorrect, le mappage de l’entité peut être régénéré dans le formulaire Mappage .
- Pour ce faire, cliquez sur Générer le mappage source .Un message s’affichera vous demandant « Voulez-vous générer le mappage à partir de zéro? »
- Cliquez sur Oui pour régénérer le mappage.
Générer des données
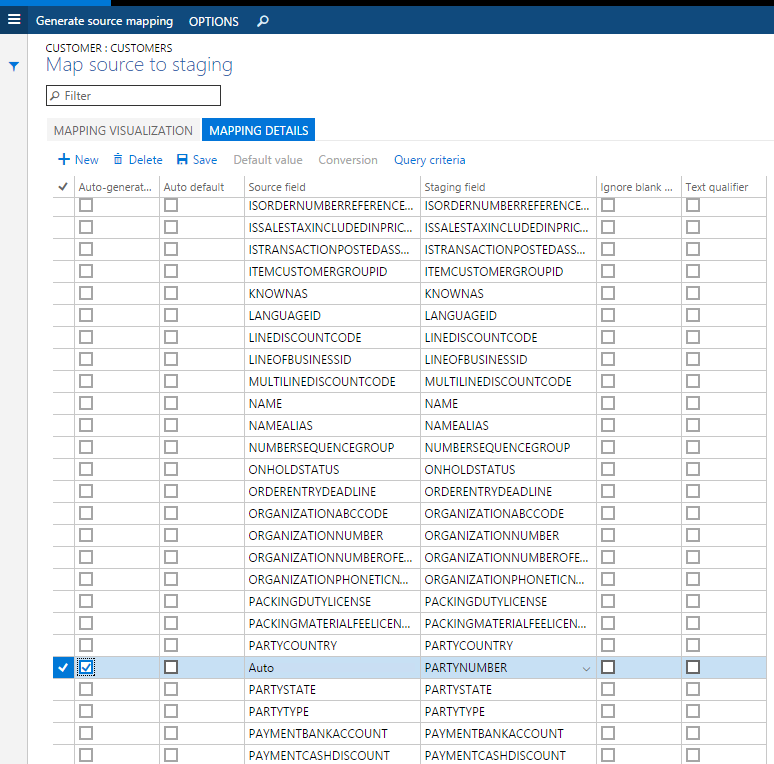
Si vous avez des champs dans des entités pour lesquelles vous souhaitez que le système génère des données lors de l’importation, au lieu de fournir les données dans le fichier source, vous pouvez utiliser la fonctionnalité générée automatiquement dans les détails de mappage de l’entité. Par exemple, si vous souhaitez importer des clients et des informations d’adresse client, mais que les informations d’adresse n’ont pas été précédemment importées avec les entités du carnet d’adresses global, vous pouvez demander à l’entité de générer automatiquement le numéro de partie lors de l’importation et les informations GAB seront créées. Pour accéder à cette fonctionnalité, affichez la carte de l’entité et cliquez sur l’ onglet Détails du mappage . Sélectionnez les champs que vous souhaitez générer automatiquement. Cela changera le champ source en Auto .
Désactiver les séquences de nombres générées automatiquement
De nombreuses entités prennent en charge la génération automatique d’identificateurs en fonction de la configuration de la séquence de numéros. Par exemple, lors de la création d’un produit, le numéro de produit est généré automatiquement et le formulaire ne vous permet pas de modifier les valeurs manuellement.

Il est possible d’activer l’attribution manuelle de séquences de numéros pour une entité spécifique.
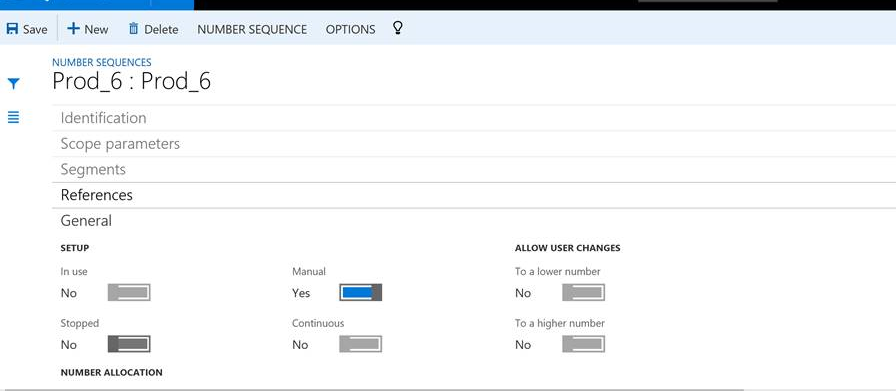
Une fois que vous avez activé l’attribution manuelle, vous pouvez fournir des numéros attribués manuellement à la place.
Exportation
L’exportation est le processus de récupération des données d’un système à l’aide d’entités de données. Le processus d’exportation se fait via un projet. Lors de l’exportation, vous disposez d’une grande flexibilité quant à la définition du projet d’exportation. Vous pouvez choisir les entités de données à exporter, mais aussi le nombre d’entités, le format de fichier utilisé (il y a 14 formats différents à choisir pour l’exportation), et appliquer un filtre à chaque entité pour limiter ce qui est exporté. Une fois les entités de données insérées dans le projet, le séquençage et le mappage décrits précédemment peuvent être effectués pour chaque projet d’exportation.

Une fois le projet créé et enregistré, vous pouvez exporter le projet pour créer un travail. Pendant le processus d’exportation, vous pouvez voir une vue graphique de l’état du travail et du nombre d’enregistrements. Cette vue affiche plusieurs enregistrements afin que vous puissiez consulter l’état de chaque enregistrement avant de télécharger les fichiers réels.

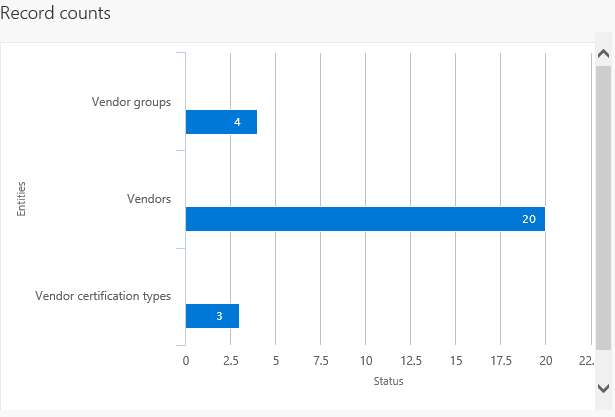
Une fois le travail terminé, vous pouvez choisir comment télécharger les fichiers: chaque entité de données peut être un fichier distinct, ou en combinant les fichiers dans un package. S’il y a plusieurs entités de données dans le travail, le choix de l’option de package accélérera le processus de téléchargement. Le package est un fichier zip, contenant un fichier de données pour chaque entité ainsi qu’un en-tête et un manifeste de package. Ces documents supplémentaires sont utilisés lors de l’importation afin d’ajouter les fichiers de données aux entités de données correctes et de séquencer le processus d’importation.
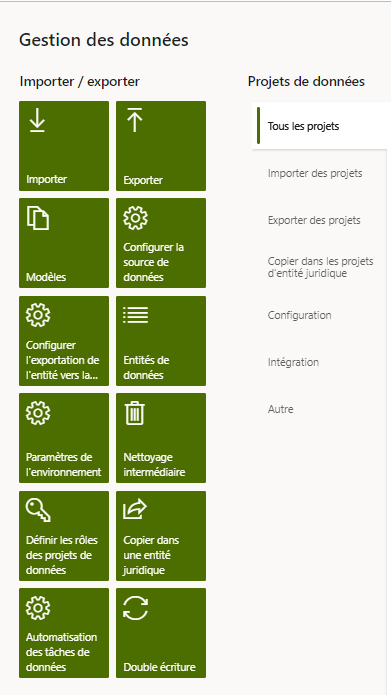
Importer
L’importation est le processus d’extraction de données dans un système à l’aide d’entités de données. Le processus d’importation est effectué via la vignette Importer dans l’ espace de travail Gestion des données . Les données peuvent être importées pour des entités individuelles ou pour un groupe d’entités logiquement liées qui sont séquencées dans le bon ordre. Les formats de fichier varient en fonction du type d’importation. Pour une entité, il peut s’agir d’un fichier Excel séparé par des virgules, des tabulations ou du texte. Pour un package de données, il s’agit d’un fichier .zip. Dans les deux cas, les fichiers sont exportés en utilisant le processus d’exportation mentionné ci-dessus.
Importer un package de données
- Connectez-vous à l’environnement en utilisant une connexion avec des privilèges suffisants (il s’agit généralement du rôle d’administrateur).
- Dans le tableau de bord, cliquez sur l’ espace de travail Gestion des données .
- Cliquez sur la vignette Importer .
- Sur la page suivante, procédez comme suit:
Importer plusieurs packages de données
Utilisez l’une des méthodes suivantes pour importer plusieurs packages de données.
- Créez un nouveau travail pour chaque package, puis répétez les étapes 4 (a) à 4 (d) ci-dessus, pour chaque package.
- Créez un travail pour importer plusieurs packages dans une séquence. Répétez les étapes 4 (a) à 4 (c) ci-dessus, puis répétez l’étape 4 (c) pour tous les packages qui doivent être importés. Après avoir sélectionné les packages, exécutez l’étape 4 (d) pour importer les données des packages de données sélectionnés via un seul travail.
Après avoir cliqué sur Importer , les données seront importées via des tables intermédiaires. La progression de l’importation peut être suivie à l’aide du bouton Actualiser dans le coin supérieur droit de l’écran.
Dépanner le traitement des paquets de données
Cette section fournit des informations de dépannage pour les différentes étapes du traitement des paquets de données.
- Les détails de l’état et des erreurs d’un travail planifié se trouvent dans la section Historique des travaux du formulaire Gestion des données .
- Les détails d’état et d’erreur des exécutions précédentes pour les entités de données peuvent être affichés en sélectionnant un projet de données et en cliquant sur Historique des travaux . Dans le formulaire Historique des exécutions , sélectionnez un travail, puis cliquez sur Afficher les données intermédiaires et Afficher le journal d’exécution . Les exécutions précédentes incluent des exécutions de projet de données qui ont été exécutées en tant que travaux par lots ou manuellement.
Dépannage du processus d’exportation
- Si vous obtenez une erreur pendant le processus d’exportation, cliquez sur Afficher le journal d’exécution et examinez le texte du journal, les détails du journal intermédiaire et Infolog pour plus d’informations.
- Si vous obtenez une erreur pendant le processus d’exportation avec une note vous invitant à ne pas ignorer la mise en scène, désactivez l’ option Ignorer la mise en scène , puis ajoutez l’entité. Si vous exportez plusieurs entités de données, vous pouvez utiliser le bouton Ignorer la mise en attente pour des entités de données individuelles.
Dépannage du processus d’importation
Lors du téléchargement de fichiers d’entité de données:
- Si les entités de données ne s’affichent pas dans les fichiers et entités sélectionnés après avoir cliqué sur Télécharger pendant le processus d’importation, attendez quelques minutes, puis vérifiez si le pilote OLEDB est toujours installé. Sinon, réinstallez le pilote OLEDB. Le pilote est le moteur de base de données Microsoft Access 2010 redistribuable – AccessDatabaseEngine_x64.exe.
- Si les entités de données s’affichent dans les fichiers et entités sélectionnés avec un avertissement après avoir cliqué sur Télécharger pendant le processus d’importation, vérifiez et corrigez le mappage des entités de données individuelles en cliquant sur Afficher la carte . Mettez à jour le mappage et cliquez sur Enregistrer pour chaque entité de données.
Lors de l’importation d’entités de données:
- Si les entités de données échouent (affichées avec un X rouge ou une icône de triangle jaune sur la vignette d’entité de données) après avoir cliqué sur Importer , cliquez sur Afficher les données de transfert sur chaque vignette sous la page Récapitulatif de l’ exécution pour examiner les erreurs. Triez et faites défiler les enregistrements avec Statut de transfert = Erreur pour afficher les erreurs dans la section Message. Téléchargez la table de préparation. Corrigez un enregistrement (ou tous les enregistrements) directement lors de la préparation en cliquant sur Modifier, Valider tout et Copier les données vers la cible , ou corrigez le fichier d’importation (et non le fichier intermédiaire) et réimportez les données.
- Si les entités de données échouent (affichées avec une icône en forme de x rouge ou de triangle jaune sur la vignette d’entité de données) après avoir cliqué sur Importer et que Afficher les données intermédiaires ne montre aucune donnée, revenez à la page de résumé de l’ exécution . Accédez à Afficher le journal d’exécution , sélectionnez l’entité de données et consultez le texte du journal, les détails du journal intermédiaire et Infolog pour plus d’informations. Les détails du journal de transfert afficheront les détails de la colonne d’erreur (champ) et la description du journal décrira les erreurs en détail.
- Si les entités de données échouent, vous pouvez vérifier le fichier d’importation pour voir s’il y a une ligne supplémentaire dans le fichier avec du texte qui affiche, « Ceci est une chaîne qui est insérée dans Excel en tant que cellule factice pour que la colonne prenne en charge plus de 255 caractères . Par défaut, un composant de destination Excel ne prend pas en charge plus de 255 caractères. Le type par défaut d’Excel sera défini en fonction des premières lignes « . Cette ligne est ajoutée lors de l’exportation des données. Si cette ligne existe, supprimez cette ligne, reconditionnez l’entité de données et essayez d’importer.
Fonctionnalités pilotées dans la gestion des données et activant les fonctionnalités pilotées
Les fonctionnalités suivantes sont activées via le flight. La diffusion est un concept qui permet à une fonction d’être activée ou désactivée par défaut.
| Nom du vol | La description |
|---|---|
| DMFEnableAllCompanyExport | Active l’exportation BYOD de toutes les sociétés dans le même travail d’exportation (pris en charge uniquement pour BYOD et non pour les fichiers). Par défaut, c’est OFF. Ce vol n’est plus nécessaire après la mise à jour 27 de la plate-forme, car cette fonctionnalité peut être activée à l’aide d’un paramètre dans les paramètres du cadre de gestion des données. |
| DMFExportToPackageForceSync | Permet l’exécution synchrone de l’exportation de l’API du package de données. Par défaut, il est asynchrone. |
| EntityNamesInPascalCaseInXMLFiles | Active le comportement où les noms d’entité sont en Pascal Case dans les fichiers XML pour les entités. Par défaut, les noms sont en majuscules. |
| DMFByodMissingSupprimer | Active l’ancien comportement où, dans certaines conditions, certaines opérations de suppression n’étaient pas synchronisées avec BYOD à l’aide du suivi des modifications. |
| DMFDisableExportFieldsMappingCache | Désactive la logique de mise en cache lors de la création du mappage de champ cible. |
| EnableAttachmentForPackageApi | Active la fonctionnalité de pièces jointes dans l’API du package. |
| FailErrorOnBatchForExport | Active l’échec en cas d’erreur au niveau de l’unité d’exécution ou au niveau des travaux d’exportation. |
| IgnorerPreventUploadWhenZeroRecord | Désactive la fonctionnalité «Empêcher le téléchargement lorsque zéro enregistrement». |
| DMFInsertStagingLogToContainer | Par défaut, il est activé. Cela améliore les performances et les problèmes fonctionnels avec les journaux d’erreurs dans la table intermédiaire. |
| ExportWhileDataEntityListIsBeingRefreshed | Lorsqu’elle est activée, des validations supplémentaires sont effectuées sur les mappages lorsqu’un travail est planifié alors que l’actualisation de l’entité est en cours. Par défaut, c’est OFF. |
| DMFDisableXSLTTransformationForCompositeEntity | Cela peut désactiver l’application de transformations sur des entités composites. |
| DMFDisableInputFileCheckInPackageImport | Des validations supplémentaires sont effectuées pour s’assurer que si un fichier d’entité est absent d’un package de données, un message d’erreur s’affiche. Ceci est le comportement par défaut. Si nécessaire, cela peut être désactivé par ce vol. |
| FillEmptyXMLFileWhenExportingCompositeEntity | Avant la mise à jour 15 de la plate-forme, lors de l’exportation d’entités composites qui n’avaient aucun enregistrement à exporter, le fichier XML généré ne contenait aucun élément de schéma. Ce comportement peut être modifié pour afficher un schéma vide en activant ce vol. Par défaut, le comportement sera toujours de générer un schéma vide. |
| EnableNewNamingForPackageAPIExport | Un correctif a été apporté pour garantir que des noms uniques sont utilisés pour l’ID d’exécution lorsque ExportToPackage est utilisé pour les scénarios d’exportation. Des ID d’exécution en double ont été créés lorsque ExportToPackage a été appelé en succession rapide. Pour préserver la compatibilité, ce comportement est désactivé par défaut. L’activation de ce vol activera ce nouveau comportement où la nouvelle convention de dénomination pour les ID d’exécution garantira des noms uniques. |
| DMFDisableDoubleByteCharacterExport | Un correctif a été apporté pour garantir que les données peuvent être exportées lorsque le format est configuré pour utiliser le paramètre de page de codes 932. Si un problème est rencontré en relation avec les exportations sur deux octets, ce correctif peut être désactivé en désactivant ce vol pour débloquer, le cas échéant. |
| DésactiverPendingRecordFromJobStatus | Un correctif a été apporté pour garantir que les enregistrements en attente sont pris en compte lors de l’évaluation de l’état final d’une tâche d’importation. Si les implémentations ont une dépendance sur la logique d’évaluation d’état et que ce changement est considéré comme un changement de rupture pour une implémentation, cette nouvelle logique peut être désactivée à l’aide de ce vol. |
| DMFDisableEnumFieldDefaultValueMapping | Un correctif a été apporté pour garantir que les valeurs par défaut définies dans le mappage avancé pour les champs d’énumération sont correctement enregistrées dans le fichier manifeste du package de données lors de la génération du package de données. Cela permet au package de données d’être utilisé comme modèle pour les intégrations lorsque de tels mappages avancés sont utilisés. Ce correctif est protégé par ce vol et peut être désactivé si le comportement précédent est toujours nécessaire (qui consiste à toujours définir la valeur sur 0 dans le manifeste du package de données). |
| DMFXsltEnableScript | Ce vol s’applique uniquement à la mise à jour 34 de la plate-forme et aux environnements hors production. Un correctif a été apporté dans la mise à jour 34 de la plate-forme pour empêcher la création de scripts dans XSLT. Cependant, cela a entraîné la rupture de certaines fonctionnalités qui dépendaient de la création de scripts. En conséquence, ce vol a été activé par Microsoft dans tous les environnements de production à titre préventif. Dans les environnements hors production, cela doit être ajouté par les clients s’ils rencontrent des échecs XSLT liés à la création de scripts. À partir de la mise à jour 35 de la plate-forme, une modification de code a été apportée pour annuler la modification de la mise à jour 34 de la plate-forme afin que ce vol ne s’applique pas à partir de la mise à jour 35 de la plate-forme. Même si vous avez activé ce vol dans la mise à jour 34 de la plate-forme, la mise à niveau vers la mise à jour 35 de la plate-forme n’aura aucun impact négatif car ce vol est activé à partir de la mise à jour 34 de la plate-forme. |
| DMFExecuteSSISInProc | Ce vol est désactivé par défaut. Cela est lié à un correctif de code qui a été conçu pour exécuter SQL Server Integration Services (SSIS) en dehors du processus afin d’optimiser l’utilisation de la mémoire de SSIS lors de l’exécution de travaux DIXF. Toutefois, cette modification a provoqué une régression dans un scénario dans lequel si le nom du projet de données DIXF contient une apostrophe (‘), le travail échouera avec une erreur. Si vous rencontrez ce problème, la suppression du (‘) dans le nom du projet de données résoudra l’échec. Cependant, si pour une raison quelconque le nom ne peut pas être changé, ce vol peut être activé pour surmonter cette erreur. L’activation de ce vol entraînera l’exécution de SSIS en cours comme auparavant, ce qui pourrait entraîner une consommation de mémoire plus élevée lors de l’exécution de travaux DIXF. |
Les étapes suivantes permettent un vol dans un environnement hors production. Exécutez la commande SQL suivante.
Pour activer les vols dans un environnement de production, un cas de support doit être enregistré auprès de Microsoft.
- Après avoir exécuté l’instruction SQL, assurez-vous que ce qui suit est défini dans le fichier web.config sur chacun des AOS. add key = « DataAccess.FlightingServiceCatalogID » value = « 12719367 »
- Après avoir apporté la modification ci-dessus, effectuez un IISReset sur tous les AOS.SQLPhotocopieuse
INSERT INTO SYSFLIGHTING ([FLIGHTNAME] ,[ENABLED] ,[FLIGHTSERVICEID] ,[PARTITION] ,[RECID] ,[RECVERSION] ) VALUES ('name', 1, 12719367, PARTITION, RECID, 1) - Partition – ID de partition de l’environnement, qui peut être obtenu en interrogeant (sélection) pour n’importe quel enregistrement. Chaque enregistrement aura un ID de partition qui doit être copié et utilisé ici.
- RecID – Même ID que la partition. Cependant, si plusieurs vols sont activés, il peut s’agir de l’ID de partition + ‘n’ pour s’assurer qu’il a une valeur unique
- RecVersion = 1
Ressources supplémentaires
@Thierry : Cet article est un peu technique et si vous avez besoin de conseils sur la gestion des entités de données et l’intégration de celles-ci dans la solution D365HR), n’hésitez pas à me faire signe ..



{kind=link}
{kind=link}